
فهرست مطالب
چکیده
محققان در زمینه عصبشناختی احساسی دریافته اند که موسیقی میتواند بر فعالیت مغزی تاثیر بگذارد . انواع مختلف موسیقی را میتوان براساس آنالیز اثرات آنها بر روی امواج مغزی شناسایی کرد . محققان میتوانند شبکههای عصبی بسازند تا رابطه بین امواج مغزی و موسیقی را پیدا کنند؛با این حال ، دادههای استخراجشده از الکتروانسفالوگرام ها اغلب حاوی اطلاعات اضافی یا بیربط هستند ، که ممکن است کارایی مدل ساخته شده و دقت طبقهبندی را کاهش دهد . در این مقاله، شبکه عصبی ساخته شده که هدف آن استفاده از داده های لوب پیشانی (جمع آوری شده توسط الکتروانسفالوگرام) برای پیشبینی نوع موسیقی (از میان سه نوع موسیقی مختلف) است بررسی میشود . دقت اعتبار شبکه اولیه (۴۷ درصد) در مقایسه با مدل رحمان و همکاران [۱] کم است.( 97.5٪).به دلیل تفاوت دقت اعتبار شبکه ها از چهار مدل برای حذف نقاط داده اضافی استفاده شده است؛ این مدلها همچنین میتوانند اهمیت حوزههای ورودی براساس معیارهای کارکردی را محاسبه کنند. با توجه به رتبهبندی مدل های خروجی و با حذف پنج ورودی مهم ، دقت اعتبار سنجی میتواند از حدود ۴۷ درصد به حدود ۴۲ درصد کاهش یابد. همچنین با حذف پنج مورد از ورودی های کم اهمیت تر، عملکرد مدل خیلی تحتتاثیر قرار نخواهد گرفت و صحت اعتبار سنجی همچنان در حدود ۴۷ درصد باقی خواهد ماند . این نتایج نشان میدهد که تکنیکهای استفاده شده در این مقاله در حذف کردن اطلاعات نامربوط موثر هستند و برای تجزیه و تحلیل تاثیرات موسیقی بر امواج مغزی مفید خواهند بود .
کلمات کلیدی: فعالیت مغز، عصب شناسی عاطفی، الکتروانسفالوگرام، شبکه عصبی، طبقه بندی، داده کاوی، اقدامات عملکردی.
مقدمه
رابطه بین موسیقی و فعالیت مغز برای محققان حوزه علوم اعصاب عاطفی موضوعی بسیار قابل توجه است و تصور میشود که موسیقی در درمان تنش و احساسات منفی مفید باشد [۲]. همچنین ، به نظر میرسد موسیقی میتواند توانایی خواندن کودکان و توانایی عملکرد ریاضی آن ها را بهبود بخشد. [۳] رحمان و همکاران [۱] مدل طبقهبندی با استفاده از شبکه عصبی ساختهاند که میتواند نوع موسیقی را براساس الگوهای امواج مغزی طبقهبندی کند دقت این مدل طبقه بندی میتواند تا ۵.۹۷ % برسد . محققان با تحلیل اثرات انواع مختلف موسیقی بر فعالیت مغز ، میتوانند تشخیص دهند کدام نوع موسیقی اثرات مثبت و کدام نوع آن اثرات منفی بر مغز انسان میگذارد .
هدف اصلی این مقاله، استفاده از شبکههای عصبی برای طبقهبندی نوع موسیقی (در سه گروه موسیقی) براساس دادههای استخراجشده به وسیله الکتروآنسفالوگرام از لوب پیشانی ۲۴ شرکت کننده است. ( این داده ها توسط رحمان و همکاران [۱] فراهم شده.) با انتخاب این مجموعه به خصوص دادهها میتوانیم نتایج خود را با نتایج رحمان مقایسه و هر دو سری داده را تحلیل کنیم. این شبکههای عصبی با استفاده ازروش انتشار معکوس خطا آماده شدهاند. توپولوژی شبکه اولیه ۳-۴۰-۲۶ ، از لینکهای وزن دار ساده برای اتصال هر عصب یک لایه به هر نورون در لایه بعد ، بدون اتصالات میانی و اتصالات چند لایه استفاده میشود.
تابع فعالسازی تابع سیگموئیدی است و بهینهساز آدمی است. پس از تشکیل شبکه عصبی، مجموعه داده اولیه به مجموعه دادههای آموزشی،اعتبارسنجی و تست نسبت داده میشود. با افزایش نرخ یادگیری ۰۱.۰ ، شبکه با بالاترین صحت سنجی از مرحله اول انتخاب و صحت تست برای خالص انتخابشده به عنوان یک روش ارزیابی برای مدل محاسبه میشود.
وظیفه دیگر این مقاله حذف کردن نقاط داده زائد و تلاش برای بهبود صحت تست است. برای انجام این کار، چهار مدل مختلف (معرفی شده توسط گیدیون) برای حذف کردن ورودیها براساس معیارهای عملکردی بهکار گرفته شده [۵].
این مقاله، موارد ذکر شده را تسهیل میکند:
- تحلیل خودکار الکتروانسفالوگرام و تشخیص رفتار امواج مغزی زمانی که تحت تاثیر انواع مختلف موسیقی هستند.این پژوهش در یافتن ژانر موسیقی مناسب برای درمان روانشناختی و رشد مهارتهای یادگیری کودکان کمک میکند.
- رتبهبندی و تناسب ورودیهای انتخاب شده. این مقاله یک روش موثر برای دادهکاوی را نشان میدهد. محدودیتها و روش کار آن نیز مورد بحث قرار خواهد گرفت .
روش
مرحله پیشپردازش شامل استاندارد سازی و انتقال کد برای تبدیل مجموعه دادهها به مجموعه ای مناسبتر برای آموزش استفاده میشود. چهار مدل ( مدل W ،U ،I و C ) برای طبقهبندی ورودیهای براساس معیارهای کارکردی آنها اعمال میشود. اصلاحاتی در این مدلها برای تناسب دادهها انجام شدهاست.
اقدامات کارکردی
اقدامات کارکردی میتوانند شباهت بین دو نورون پنهان را بر روی یک مجموعه آموزشی تعیین کنند که به محاسبه زوایا بین بردارهای نتایج فعالسازی از نورونها بستگی دارد [۶] . این فرمول آن است.
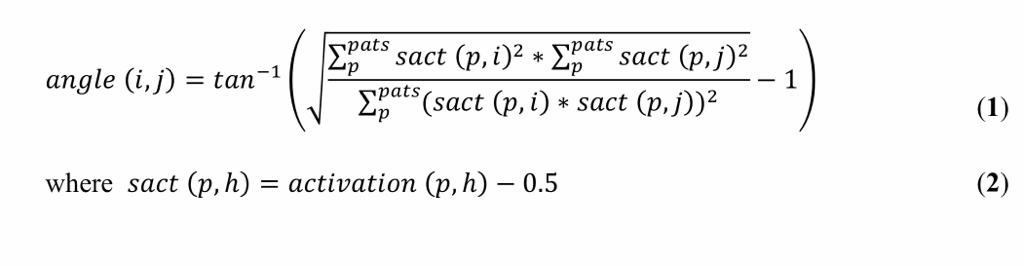
گیدیون این تکنیک را گسترش داد و هم اکنون این تکنیک میتواند شباهت بین دو نورون پنهان را براساس ماتریس وزن مشخص کند [۷] . برای ارزیابی ورودیها ، این تکنیک باید برای محاسبه بردارهای ماتریس وزن به حوزههای ورودی مختلف تغییر داده شود [۵] . در اینجا فرمول جدید معادله (۲) آمدهاست.
![]()
در معادله (۳) ، ماتریس وزن نرمال شدهاست . با کاستن ۰.۵ ، حدود نیمی از مقادیر موجود در ماتریس مثبت و بقیه منفی خواهند بود ، که منجر به زوایای خروجی بهتری خواهد شد . در این مقاله ، با توجه به مشخصه مجموعه دادهها و عملکرد مدل ، این معادله برای استفاده از استانداردسازی اصلاح شدهاست . فرمول جدید معادله (۳) ، که در مدل W مورد استفاده قرار میگیرد:
همچنین ، این تکنیک را میتوان برای تحلیل خود دادههای ورودی نیز تنظیم کرد . در این حالت ، هر ستون ویژگی به عنوان یک بردار برای محاسبه زاویه ها در نظر گرفته خواهد شد [۵] . در اینجا فرمول جدید معادله (۲) آمدهاست.
![]()
همانطور که ذکر شد ، در این مقاله جای نرمالیزاسیون از استانداردسازی برای مجموعه دادهها استفاده میشود . بنابراین ، معادله (۵) نیز باید اصلاح شود . در اینجا فرمول جدید معادله (۵) که در مدل I استفاده میشود آورده شدهاست.
اگر یک زاویه بین دو میدان ورودی به ۹۰ درجه نزدیک باشد ، نشان میدهد که این دو ورودی کمتر شبیه هم هستند . زوایای کوچک ( < ۱۵ درجه ) نشاندهنده شباهت زیاد و زوایای بسیار بزرگ ( > ۱۶۵ ) نشان میدهند که آنها به طور موثر مکمل یکدیگر هستند ، و همه زوجهای ورودی با آن دو نوع زاویه باید حذف شوند [۶] . برای مجموعه دادههای این مقاله ، جفت ورودی ها به ترتیب صعودی، براساس فواصل زاویهای آنها با ۹۰ درجه مرتب میشوند . در این لیست ترتیب بندی شده ، پنج ورودی منحصر به فرد به عنوان ورودیهای قابلتوجه و آخرین پنج ورودی منحصر به فرد به عنوان مهمترین ورودیها استخراج میشوند و خروجیهای مدل W و I خواهند بود؛ این مقاله عملکرد شبکههای اولیه را با شبکههایی که بیشترین/ کمترین ورودیهای مهم را حذف کردهاند، مقایسه میکند.
برای مدل C (مجموع I ) و U (مجموع W )، به جای دستهبندی زوجهای ورودی ، آنها با مرتبسازی زاویه میانگین هر ورودی به تمام ورودیهای دیگر ایجاد میشوند .
در این تکنیک ، اندازههای عملکردی برای مجموعه دادههای این مقاله مناسب است . در طی این دوره آموزشی ، دقت آموزشی به ۱۰۰ درصد نزدیک خواهد بود ، اما دقت / اعتبار سنجی آزمون هرگز بالاتر از ۵۰ درصد نیست که با توصیف گیدیون مطابقت دارد. توصیف وی از این قرار است که : این مجموعه دادهها ممکن است حاوی اطلاعات بیربط یا اضافی باشند [۵]. بنابراین ، با اعمال اقدامات کاربردی ، بسیاری از نقاط داده اضافی به طور موثر و کارآمد حذف خواهند شد .
دادههای مورد نظر برای بررسی اندازه این مجموعه داده عبارتند از:
۱ .اولین خصوصیت تعداد شرکتکننده ، p1 و p2 است . آخرین ویژگی ، برچسبهای نوع موسیقی ، برای موسیقی کلاسیک ، و برای موسیقی پاپ است .
دیگر ویژگیها عبارتند از : میانگین ، حداکثر ، حداقل ، انحراف معیار ، دامنه میان چارکی ، واریانس ، مجموع ، کجی، میزان تیزی اوج منحنی، کشیدگی ، کمیت ،میانگین مطلق ، آنتروپی شانون ،. بنابراین ، خصوصیت اول و آخر هر دو داده اسمی هستند که با اعداد صحیح نمایش داده میشوند در حالی که خصوصیتهای دیگر شناور هستند .
شکل ۱ . بخشی از آمار خلاصه دادهها ، تولید شده توسط تابع ” توصیف ( ) ”
همانطور که در شکل ۱ نشاندادهشده ، با مقایسه بیشترین مقدار میانگین _ F7 و var _ F7 ، محدوده ورودیها بسیار متنوع است. این نشان میدهد که برخی از فرآیندهای پیش از بلوغ مانند نرمال سازی، ممکن است برای سادهتر کردن آموزش مدل بکار گرفته شوند .
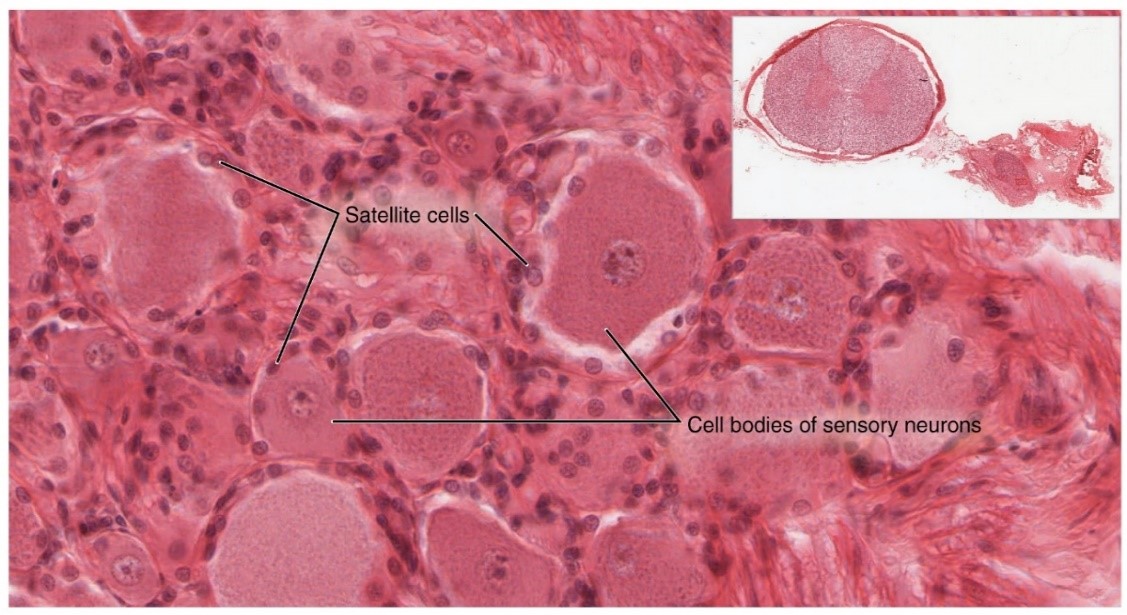
شکل ۲ . نمودار های جعبه ای. برای نمایش توزیع های هر ورودی (۲۶ویژگی اول) این مجموعه داده پس از مراحل اولیه پیش پردازش (نرمال سازی متغیرهای عددی)
همانطور که در شکل ۲ نشاندادهشده ، بسیاری از ورودیها دارای حاوی مقادیر زیادی داده پرت هستند ، که نشان میدهد قرار دادن داده ها در بازه ای بین ۰ و ۱ مناسب نیست. علاوه بر این، برای مدل I و C ، زمانی که بکارگیری مقیاسهای عملکردی بر روی خود ورودیها ، ورودیهای نرمال شده با بسیاری از داده های پرت به احتمال زیاد دارای بردارهای متفاوتی هستند . در این حالت ، زوایای بین ورودیها همه یکسان خواهند بود ، و تعیین ورودیهای قابلتوجه سخت خواهد بود . بنابراین برای اعمال معیارهای عملکردی ، به طور خاص مراحل قبل از پردازش برای مجموعه دادهها باید برای به دست آوردن یک مدل با عملکرد بهتر اعمال شود .
آمادهسازی داده
ابتدا، برای مشخصه هدف ” برچسب ” ، مقدار آن از ” ۱ ، ۲ ، ۳ ” تا ” ۰ ، ۱ و ۲ ” به منظور استفاده از تابع متقابل آنتروپی در شبکه برای طبقهبندی امکان پذیر شود. هر ژانر موسیقی دارای همان تعداد نقاط داده میباشد که ۱۹۲ مورد است .
سپس ، تمام ویژگیهای مشخصه ( همه صفات ” برچسبهای ” ) با کم کردن مقدار میانگین و تقسیمبر انحراف استاندارد ویژگی استاندارد شدهاند . همان طور که در شکل ۱ نشانداده شدهاست . ۳ ، این فرآیند پیش از این تضمین میکند که حدود نیمی از مقدار داده مثبت خواهد بود و حدود نیمی از مقدار داده منفی خواهد بود ، که میتواند به طور مستقیم معیارهای عملکردی را در حال حاضر ( برای مدل I و C )اعمال کند.
همچنین ، «شماره موضوع » ( شماره شرکت کنندگان ) جزو دادههای اسمی است ، اما در این مقاله از هیچ پیش پردازشی برای اصلاح این ورودی استفاده نمیشود . دلیل استفاده نکردن از پیش پردازش این است که در کار کردن با دادههای اسمی آنها را با استفاده از کدبندی وان هات به چندین ستون تبدیل میکنیم. در این حالت ، حوزههای ورودی بیشتری وجود خواهند داشت و بردارهای ورودی جدید به طور قطع از هم دیگر متفاوت خواهند بود ، این تفاوت برای اعمال مقیاسهای عملکردی ارجح نیست .
مجموعه دادهای که به آن اشاره کردیم، یک زیرمجموعه است و نتایج به دست آمده بیشتر با کل مجموعه دادهها مقایسه خواهد شد ، بنابراین نامهای ویژگیها تغییر نمیکنند و همه ” ۷F ” ها را نگه میداریم، که نگهداری آنها، تجزیه و تحلیل بیشتر را برای ما آسان تر خواهد کرد .
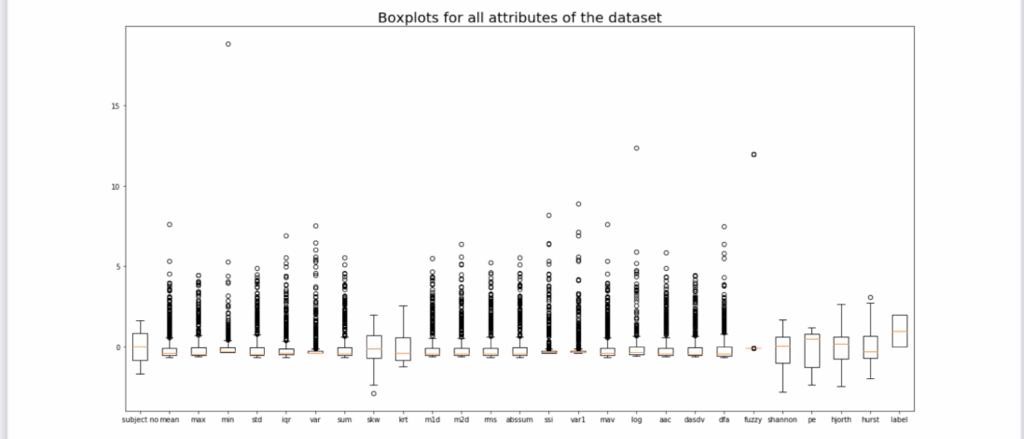
شکل ۳ . نمودار های جعبه ای برای نشان دادن توزیع هر ویژگی این مجموعه دادهها استفاده شده است. پس از پیشپردازش اختصاصی ، ترتیب ویژگیها مشابه مجموعه داده اصلی میباشد .
همانطور که در شکل ۳ نمایش داده شده، بعد از پیشپردازش اختصاصی ، همه ویژگیها آماده استفاده در شبکههای ساختاری هستند.
نتایج و بحث
همانطور که در بخش ۱ ( مقدمه ) ذکر شد ، مجموعه دادهها اولیه به آموزش ، اعتبار سنجی، و تست در نسبت
۸ : ۱ : ۱ با استفاده از دو تابع تفکیک آزمون آموزش داده میشود شبکههای عصبی فقط در مجموعه آموزشی آموزش داده خواهند شد؛ به همان صورتی که در شکل نشان داده شده.
۴، با اسکن شبکه ها در ۱۰۰۰ دوره اول، شبکه با بالاترین دقت اعتبار سنجی انتخاب می شود و همچنین می توان شبکه را بر اساس دقت تست مربوطه قضاوت کرد. همه این گامها تضمین میکنند که ارزیابی منصفانه و معتبر بوده و همه دادههای موجود برای آموزش و ارزیابی مورد استفاده قرار گرفتهاند .
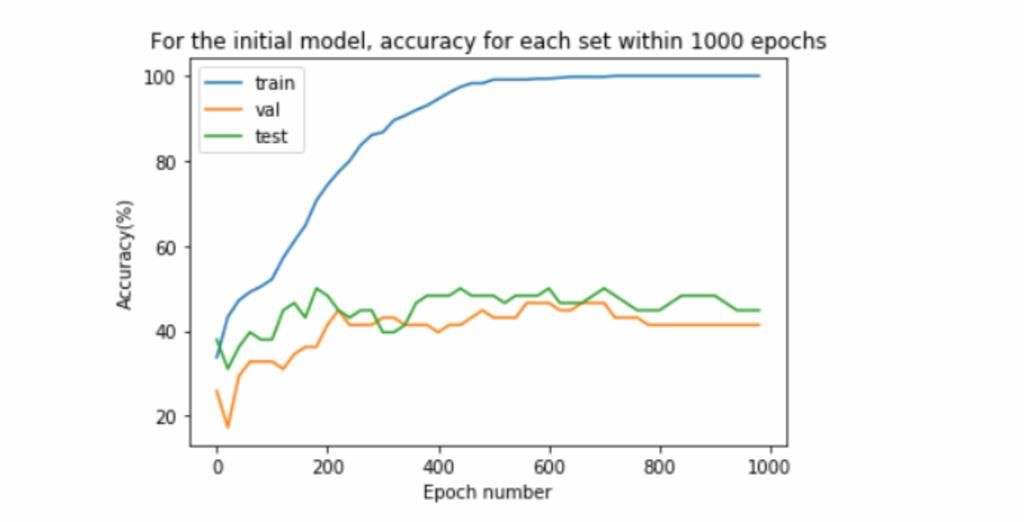
شکل ۴ . دقت برای هر مجموعه در ۱۰۰۰ دوره است. در طول ۱۰۰۰ دوره اول هنگام آموزش یک شبکه عصبی، شبکه ای را با بالاترین دقت اعتبارسنجی همراه با دقت آموزش و آزمایش آن بیابید.
برای مقایسه مدلهای ایجاد شده ، برنامه ۱۰ بار اجرا خواهد شد و نتیجه هر اجرا برای تولید یک نتیجه متوسط ثبت خواهد شد . این جدول نشاندهنده دقت متوسط هر مدل ذکر شده در این مقاله در مقایسه با نتایج ارائهشده توسط رحمان و همکاران [۱] است .
جدول ۱ . دقت متوسط (درصد گرد شده به ۲ اعشار) مدل ها برای ۱۰ دور در مقایسه با نتایج ارائهشده توسط رحمان و همکاران [۱] . برای نوع شبکه ، ( حداقل ) به این معنی است که پس از حذف پنج ورودی مهم ، یک مدل است ، در حالی که ( اغلب ) به این معنی است که این یک مدل پس از حذف پنج ورودی مهم است.
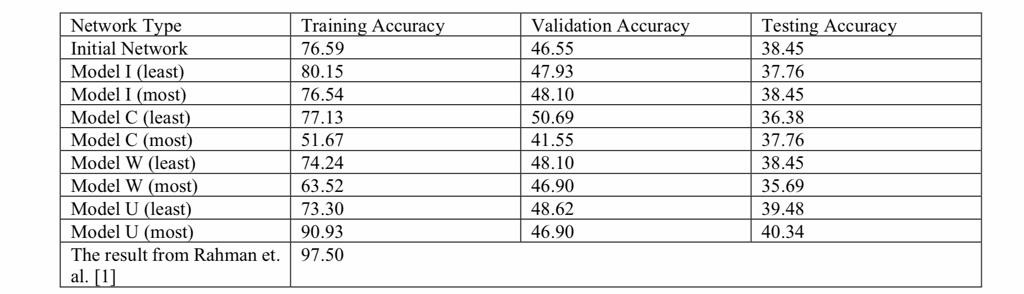
از جدول ۱ دقت در مقایسه با مدلهای این مقاله بالا (97.50 ٪) است ؛ به دلیل این که مجموعه دادههای استفادهشده در این مقاله زیر مجموعهای از مدل از رحمان و همکاران [۱] است و ممکن است حاوی اطلاعات کافی برای ساخت یک مدل با دقت بالا نباشد .
برای این سه دقت ، دقت آموزشی نشان دهنده احتمال بیش از حد برازش مدل است و دقت آزمایش یک روش ارزیابی اضافه بر سازمان است ، در حالی که به صحت اعتبار باید توجه بیشتری پرداخته شود.
با مقایسه صحت اعتبار سنجی مدل هایی که ۵ ورودی با اهمیت کمتر آنها حذف شده، مشاهده میشود که عملکرد مدل ها زیاد تغییر نمیکند( حدود ۴۷ ٪ ) ، که نشان میدهد معیارهای عملکردی [۵] یک تکنیک مناسب برای حذف اطلاعات اضافی هستند ، و این روش با اهداف بیانشده این مقاله مطابقت دارد . در حالی که مدلها ۵ ورودی مهم را حذف کردند ، تنها مدل C یک اثر بد واضح بر عملکرد مدل را نشان داد ( از ۴۷ ٪ تا ۴۲ ٪ ) ، پس نتیجه گیری میشود که مقیاسهای عملکردی [۵] همچنان دارای محدودیتهایی هستند.
نتیجهگیری و کار آینده
در این مقاله ، شبکههای عصبی برای طبقهبندی انواع موسیقی براساس ویژگیهای استخراجشده از لوب قدامی مغز ساخته شدهاند و تکنیک اقدامات کارکردی برای حذف ورودیهای بیربط به کار رفتهاست . از نتایج بخش ۳ ، امتیاز آموزشی بالا است ( میتواند تا ۱۰۰ درصد برسد ) ، اما امتیاز اعتبار سنجی / آزمون پایین است ( خطای اعتبار سنجی میانگین ۴۷ درصد است ) ، که بسیار کمتر از رحمان است . نتیجه ( 97.50 ٪ ) [۱] . در مقایسه با رحمان و همکاران. شبکههای موجود در جدول تنها از دادههای بخش قدامی به جای کل مغز استفاده میکنند و اطلاعات موجود در مجموعه دادهها کمتر و اضافی است ، بنابراین این نتیجه پذیرفته شدهاست .
برای حذف اطلاعات اضافی ، تکنیک اقدامات کارکردی یک روش خوب است (۵) . اصلاحاتی در هر دو مجموعه داده و تکنیکهای کارکردی اعمال شدهاست ، که در بخش ۲.۱ و ۲.۳ توضیح داده شدهاست تا اطمینان حاصل شود که این تکنیک بطور مناسب بر روی مجموعه دادهها اجرا خواهد شد . با تجزیه و تحلیل نتایج این چهار مدل با استفاده از معیارهای کارکردی ، این مقاله نشان میدهد که می توان از معیارهای کارکردی برای حذف حداقل ورودیها و کار به طور موثر استفاده کرد ، چرا که عملکرد مدل تحتتاثیر قرار نخواهد گرفت . اما این روش همچنین دارای محدودیتهایی است که برای پیدا کردن بیشتر ورودی ها مورد استفاده قرار میگیرد . در میان این ۴ مدل ، تنها نتایج مدل C نشان میدهد که عملکرد مدل کاهش قابلتوجهی ( ۵ ٪ ) دارد . این مدرک حاکی از آن است که معیارهای کارکردی نمیتواند ورودی را به طور پایدار در مجموعه دادهها با اطلاعات کمتر پیدا کند .
برای کار آینده ، معیارهای کارکردی باید در کل مجموعه دادهها اعمال شوند به جای زیر مجموعه برای بررسی بیشتر عملکرد آن در یافتن ورودی . علاوه بر این، برای مدل W وU آنها ورودیهای متفاوتی براساس ماتریس وزن موجود خواهند داشت ، بنابراین اگر قابلیت اطمینان ماتریس وزن فعلی پایین باشد و نمیتواند مدلهایی را با امتیاز اعتبار سنجی بالا ارائه دهد ، تاثیر اقدامات کارکردی نیز کوچک خواهد بود . تلاشهای بیشتری باید برای به حداقل رساندن تاثیر منفی مدلها با استفاده از تکنیک معیارهای کارکردی اتخاذ شود.
